
Merging And The Merge Output Editor Window
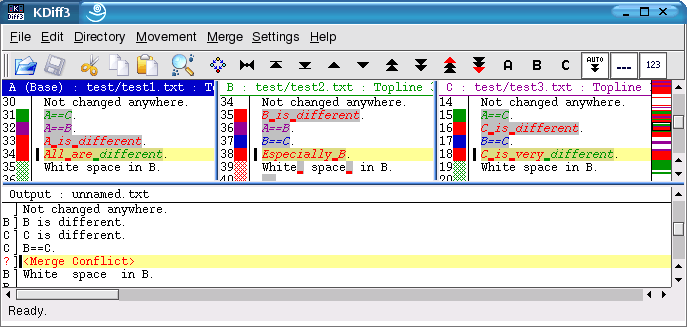
The merge output editor window (below the diff input windows) also has an info line at the top showing "Output:", the filename and "[Modified]" if you edited something. Usually it will contain some text through the automatic merge facilities, but often it will also contain conflicts.
!!! Saving is disabled until all conflicts are resolved !!! (Use the "Go to prev/next unsolved conflicts"-buttons to find the remaining conflicts.)
With only two input files every difference is also a conflict that must be solved manually.
With three input files the first file is treated as base, while the second and third input files contain modifications. When at any line only either input B or input C have changed but not both then the changed source will automatically be selected. Only when B and C have changed on the same lines, then the tool detects a conflict that must be solved manually. When B and C are the same, but not the same as A, then C is selected.
The merge output editor window also has a summary column on the left. It shows the letter of the input from which a line was selected or nothing if all three sources where equal on a line. For conflicts it shows a questionmark "?" and the line shows "<Merge Conflict>", all in red. Because solving conflicts line by line would take very long, the lines are grouped into groups that have the same difference and conflict characteristics. But only-white-space-conflicts are separated from non-white-space-conflicts in order to ease the merging of files were the indentation changed for many lines.
When clicking into the summary column with the left mouse button in either window then the beginning of the group belonging to that line will shown in all windows. This group then becomes the "current group". It is highlighted with the "Current range (diff) background color" and a black bar appears on the left side of the text.
The button bar below the menubar contains three input selector buttons containing the letters "A", "B" and "C". Click the input selector button to insert (or remove if already inserted) the lines from the respective source. To choose the lines from several inputs click the respective buttons in the needed order. For example if you want that the lines from "B" appear before the lines from "A" in the output, first click "B", then "A".
If you use the auto-advance option ("Automatically go to next unsolved conflict after source selection"), you should disable this before choosing lines from several inputs or if you want to edit the lines after your choice. Otherwise KDiff3 will jump to the next conflict after choosing the first input.
It is often helpful directly edit the merge output. The summary column will show "m" for every line that was manually modified. When for instance the differences are aligned in a way that simply choosing the inputs won't be satisfactory, then you can mark the needed text and use normal copy and paste to put it into the merge output.
Sometimes, when a line is removed either by automatic merge or by editing and no other lines remain in that group, then the text <No src line> will appear in that line. This is just a placeholder for the group for when you might change your mind and select some source again. This text won't appear in the saved file or in any selections you want to copy and paste.
The text "<Merge Conflict>" will appear in the clipboard if you copy and paste some text containing such a line. But still be careful to do so.
The normal merge will start by solving simple conflicts automatically. But the "Merge"-menu provides some actions for other common needs. If you have to select the same source for most conflicts, then you can choose "A", "B" or "C" everywhere, or only for the remaining unsolved conflicts, or for unsolved white space conflicts. If you want to decide every single delta yourself, you can "Set deltas to conflicts". Or if you want to return to the automatic choices of KDiff3 then select "Automatically solve simple conflicts". KDiff3 then restarts the merge. For actions that change your previous modifications KDiff3 will ask for your confirmation before proceeding.
Note: When choosing either source for unsolved white space conflicts and the options "Ignore Numbers" or "Ignore C/C++ Comments" are used then changes in numbers or comments will be treated like white space too.
Many version control systems support special keywords in the file. (e.g. "$Date$", "$Header$", "$Author$", "$Log$" etc.) During the check-in the version control system (VCS) changes these lines. For instance "$Date$" will turn into "$Date: 2005/03/22 18:45:01 $". Since this line will be different in every version of the file, it would require manual interaction during the merge.
KDiff3 offers automatic merge for these items. For simple lines that match the "Auto merge regular expression"-option in all input-files KDiff3 will choose the line from B or - if available - from C. (Additionally it is necessary that the lines in question line up in the comparison and the previous line contains no conflict.) This auto merge can either be run immediately after a merge starts (activate the option "Run regular expression auto merge on merge start") or later via the merge menu "Run Regular Expression Auto Merge".
Automatic merge for version control history (also called "log") is also supported. The history automerge can either run immediately when the merge starts by activating the option "Merge version control history on merge start" or later via the merge menu "Automatically Solve History Conflicts".
Usually the version control history begins with a line containing the keyword "$Log$". This must be matched by the "History start regular expression"-option. KDiff3 detects which subsequent lines are in the history by analysing the leading characters that came before the "$Log$"-keyword. If the same "leading comment"-characters also appears in the following lines, then they are also included in the history.
During each check-in the VCS writes a unique line specifying version-, date- and time-information followed by lines with user comments. These lines form one history-entry. This history section grows with every check-in and the most recent entries appear at the top (after the history start line).
When for parallel development two or more developers check-in a branch of the file then the merge history will contain several entries that appear as conflicts during the merge of the branches. Since merging these can become very tedious, KDiff3 offers support with two possible strategies: Just insert the history information from both contributors at the top or sort the history information by a user defined key.
The just-insert-all-entries-method is easier to configure. KDiff3 just needs a method to detect, which lines belong to one history entry. Most VCS insert an empty line after each history entry. If there are no other empty lines, this is a sufficient criterion for KDiff3. Just set an empty "History entry start regular expression". If the empty line criterion isn't sufficient, you can specify a regular expression to detect the history entry start.
Note that KDiff3 will remove duplicate history entrys. If a history entry appeared several times in the history of a input file, only one entry will remain in the output.
If you want to sort the history, then you have to specify how the sort key should be built. Use parentheses in the "History entry start regular expression" to group parts of the regular expression that should later be used for the sort key. Then specify the "History entry start sort key order" specifying a comma "," separated list of numbers referring to the position of the group in the regular expression.
Because this is not so easy to get right immediately, you are able to test and improve the regular expressions and key-generation in a dedicated dialog by pressing the "Test your regular expressions"-button.
Example: Assume a history that looks like this:
/************************************************************************** ** HISTORY: $Log: \toms_merge_main_view\MyApplication\src\complexalgorithm.cpp $ ** ** \main\integration_branch_12 2 Apr 2001 10:45:41 tom ** Merged branch simon_branch_15. ** ** \main\henry_bugfix_branch_7\1 30 Mar 2001 19:22:05 henry ** Improved the speed for subroutine convertToMesh(). ** Fixed crash. **************************************************************************/The history start line matches the regular expression ".*\$Log.*\$.*". Then follow the history entries.
The line with the "$Log$"-keyword begins with two "*" after which follows a space. KDiff3 uses the first non-white-space string as "leading comment" and assumes that the history ends in the first line without this leading comment. In this example the last line ends with a string that also starts with two "*", but instead of a space character more "*" follow. Hence this line ends the history.
If history sorting isn't required then the history entry start line regular expression could look like this. (This line is split in two because it wouldn't fit otherwise.)
\s*\\main\\\S+\s+[0-9]+ (Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec) [0-9][0-9][0-9][0-9] [0-9][0-9]:[0-9][0-9]:[0-9][0-9]\s+.*For details about regular expressions please see the regular expression documentation by Trolltech. Note that "\s" (with lowercase "s") matches any white space and "\S" (with uppercase "S") matches any non-white-space. In our example the history entry start contains first the version info with reg. exp. "\\main\\\S+", the date consisting of day "[0-9]+", month "(Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec)" and year "[0-9][0-9][0-9][0-9]", the time "[0-9][0-9]:[0-9][0-9]:[0-9][0-9]" and finally the developers login name ".*".
Note that the "leading comment"-characters (in the example "**") will already be removed by KDiff3 before trying to match, hence the regular expression begins with a match for none or more white-space characters "\s*". Because comment characters can differ in each file (e.g. C/C++ uses other comment characters than a Perl script) KDiff3 takes care of the leading comment characters and you should not specify them in the regular expression.
If you require a sorted history. Then the sortkey must be calculated. For this the relevant parts in the regular expression must be grouped by parentheses. (The extra parentheses can also stay in if history sorting is disabled.)
\s*\\main\\(\S+)\s+([0-9]+) (Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec) ([0-9][0-9][0-9][0-9]) ([0-9][0-9]:[0-9][0-9]:[0-9][0-9])\s+(.*)The parentheses now contain 1. version info, 2. day, 3. month, 4. year, 5. time, 6. name. But if we want to sort by date and time, we need to construct a key with the elements in a different order of appearance: First the year, followed by month, day, time, version info and name. Hence the sortkey order to specify is "4,3,2,5,1,6".
Because month names aren't good for sorting ("Apr" would be first) KDiff3 detects in which order the month names were given and uses that number instead ("Apr"->"04"). And if a pure number is found it will be transformed to a 4-digit value with leading zeros for sorting. Finally the resulting sort key for the first history entry start line will be:
2001 04 0002 10:45:41 integration_branch_12 tom
For more information also see Merge Settings.


Would you like to make a comment or contribute an update to this page?
Send feedback to the KDE Docs Team